Fundamentals that you need to know to create modern applications with LLM's powered by MongoDB
Creating Applications with LLMs Powered by MongoDB
In this post, we will explore the fundamentals of building applications with Large Language Models (LLMs) powered by MongoDB. We will cover key concepts such as vector embeddings, vector search, semantic search, and vector databases. We will also provide practical examples and resources to help you get started with building your own applications. We will cover the following topics:
- Understanding Tokens, Vector Embeddings, and their Role in LLMs
- Implementing Vector Search with MongoDB
- Creating a Vector Index
- Inserting Vector Embeddings into MongoDB
- Performing Vector Search Queries
- Building a Semantic Search Application
- Leveraging Vector Databases for Efficient Data Retrieval
- What is Hugging Face and How to use their transformer library to powered your applications
- What is RAG.
Everything without spend a single cent, using MongoDB Atlas Free Tier and Hugging Face free models.
Understanding Tokens, Vector Embeddings, and their Role in LLMs
- Tokens: In the context of LLMs, tokens are the basic units of text that the model processes. They can be words, subwords, or characters. Tokenization is the process of breaking down text into these smaller units, which allows the model to understand and generate language effectively.
- Vector Embeddings: Vector embeddings are numerical representations of tokens that capture their semantic meaning. Each token is mapped to a high-dimensional vector space, where similar tokens are closer together.
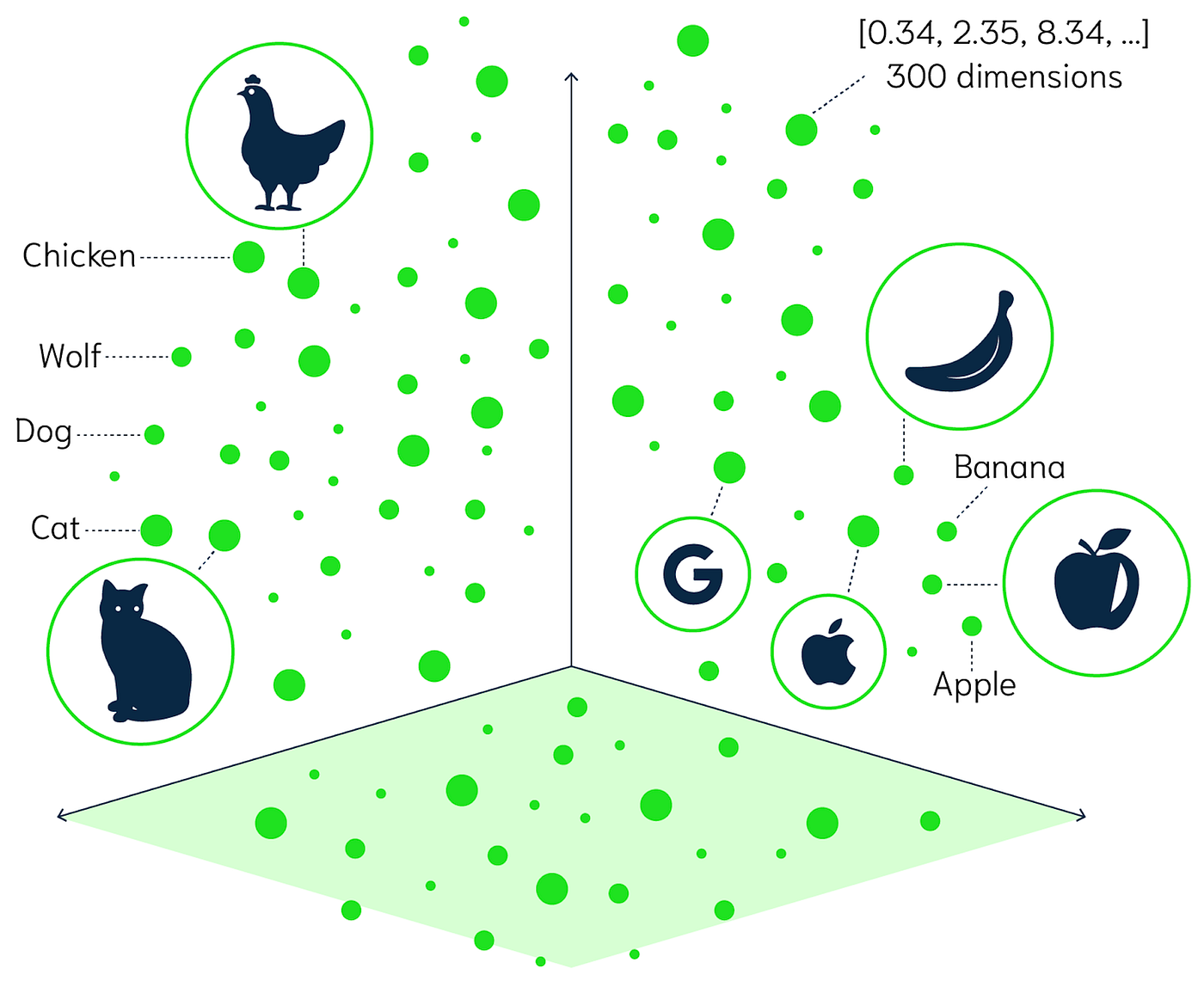
How a Multidimensional Vector Space looks like?
A multidimensional vector space is a mathematical space where each point is represented by a vector with multiple dimensions. In the context of LLMs, each token is represented as a point in this space, allowing the model to understand relationships between tokens based on their proximity in the vector space. For example, the words "king" and "queen" might be represented as vectors that are close together, while "king" and "apple" would be farther apart. This spatial representation enables the model to capture the nuances of language and perform tasks such as similarity search, clustering, and classification.
How an modern web application powered by LLMs looks like?
We know that LLMs are powerful tools but their knowledge is limited to the data they were trained on, but there are a lot of different techniques to enhance their knowledge capabilities, one of the most popular is RAG (Retrieval-Augmented Generation), which combines the generative capabilities of LLMs with external knowledge sources, In the case of our application this external source came from MongoDB. but you can't only perform a query and then pass the result to the LLM, you have to make the LLM undertand that data, and retrieve it quickly.
To understand the language that an LLM understands, we have to think how a computer understands language and not only language, everything: images, videos, audio, etc. The answer is: by using numbers, so we have to convert our data into numbers, and this is where vector embeddings come into play.
Why numbers? Because computers are great at working with numbers, and they can perform mathematical operations on them to find patterns and relationships. So we have to find a way to convert our data in vector embeddings, here is where a embeddings model comes into play, an embeddings model is a type of LLM that is trained to convert data into vector embeddings, so we can use it to convert our data into vector embeddings and then store them in MongoDB. This process is called vectorization.
But now we have to find a place where to store our vector embeddings, and this is where MongoDB comes into play with Vector Search, which allows us to store and search for vector embeddings in MongoDB. the process of store the embeddings in our Database is called Vector Indexing, and it allows us to perform semantic search queries on our data. In our process we can also call this process as Data Ingestion.
This last process is really important because we can now perform a semantic search query on our data, which means that we can find the most relevant data based on the meaning of the words, not just the exact match. This is really powerful because it allows us to find the most relevant data even if the words are not exactly the same, and then providing this information to the LLM. In this last step we can perform the Data Ingestion, with a process called chunking which allows us to break down our data into smaller pieces, to also prevent the LLM from being overwhelmed with too much information and overwhelmed its context window. ¡If you understand this process you have undertand RAG! But to do it simple lets see an example:
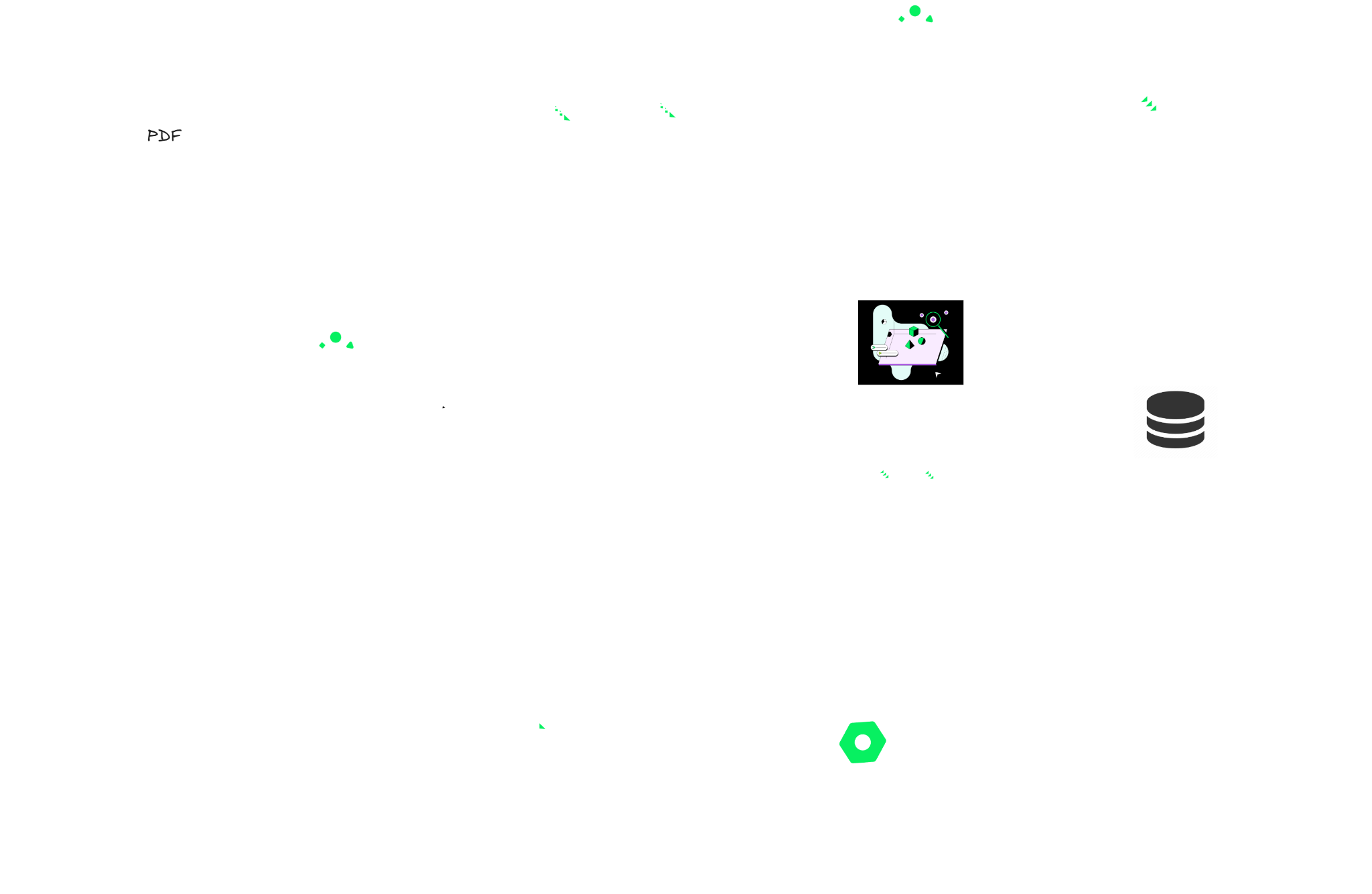
In the example above:
-
The 1 , 2 and 3 integrates the Ingest Data process.
- In the middle of 1 and 2 we have the chunking process.
- The number 3 is the place where we will store our vector, our vector database in our case MongoDb and its vector search capabilities.
-
In the rest of the diagram we have RAG, and were are going to break it down:
- The process start with the user asking question to our application. that we pass through the LLM, which is the 4. to create a semantic query.
- The 5 is the process of searching for the most relevant data in our vector database. Thank to MongoDB vector search capabilities we can perform this process really fast but also with the most relevant information.
- The next step is the 6, where we joing both the semantic query and our relevant information, and we create a prompt to get the best posible answer from the LLM.
- Whe pass our prompt to the LLM, which is the 7, and we get the answer.
- Finally, we return the answer to the user, which is the 8.
Let's get dirty with code
Prerequisites
Before we start, make sure you have the following prerequisites:
- A MongoDB Atlas account (you can sign up for a free tier account here).
- Node.js installed on your machine, (this is optional but you can choose python or any other language you prefer).
- An account on Hugging Face and an access token.
If you whant to see the code directly, you can find it in this GitHub repository and please follow the instrution on the README.
How to create Vector from text getEmbedding function:
This function will take a text and return a vector embedding using the Hugging Face transformer library, and a specific embeddings model. Is important that you have and access token from Hugging Face, you can create one here. you only need a read access token.
import { pipeline } from '@xenova/transformers';
// Function to generate embeddings for a given data source
export async function getEmbedding(data) {
const embedder = await pipeline(
'feature-extraction',
'Xenova/nomic-embed-text-v1');
const results = await embedder(data, { pooling: 'mean', normalize: true });
return Array.from(results.data);
}
Database configuration
I'm going to obviate the MongoDB connection and creation of Documents, so I previously create all of this in my MongoDB Atlas account.
How to insert vector embeddings into MongoDB
In this part we will perform the Data Ingestion process and we will provide some recommendations from mongo, so the first step is store data to our Documents:
- We will store a Movie name and its description in the
text array. - We will create a new ones if were not stores proviously.
- We will use the
getEmbeddingfunction to get the vector embeddings and then we will store them in MongoDB.
Note: the
convertEmbeddingsToBSONfunction is optional, but it is recommended to use it to convert the embeddings to BSON format, which is the format used by MongoDB to store data. This will allow you to store the embeddings in a more efficient way and also to perform vector search queries on them.
import { MongoClient } from 'mongodb';
import { getEmbedding } from '../lib/get-embeddings.js';
import { convertEmbeddingsToBSON } from './convert-embeddings.js';
// Data to embed
const texts = [
"Titanic: A seventeen-year-old aristocrat falls in love with a kind but poor artist aboard the luxurious, ill-fated R.M.S. Titanic.",
"The Matrix: A computer hacker learns from mysterious rebels about the true nature of his reality and his role in the war against its controllers.",
"Avatar: A paraplegic marine dispatched to the moon Pandora on a unique mission becomes torn between following his orders and protecting the world he feels is his home."
]
async function run() {
// Connect to your Atlas cluster
const client = new MongoClient(process.env.ATLAS_CONNECTION_STRING);
try {
await client.connect();
const db = client.db("sample_db");
const collection = db.collection("embeddings");
console.log("Generating embeddings and inserting documents...");
const insertDocuments = [];
await Promise.all(texts.map(async text => {
// Check if the document already exists
const existingDoc = await collection.findOne({ text: text });
// Generate an embedding using the function that you defined
var embedding = await getEmbedding(text);
// Uncomment the following lines to convert the generated embedding into BSON format
const bsonEmbedding = await convertEmbeddingsToBSON([embedding]); // Since convertEmbeddingsToBSON is designed to handle arrays
embedding = bsonEmbedding; // Use BSON embedding instead of the original float32 embedding
// Add the document with the embedding to array of documents for bulk insert
if (!existingDoc) {
insertDocuments.push({
text: text,
embedding: embedding
})
}
}));
// Continue processing documents if an error occurs during an operation
const options = { ordered: false };
// Insert documents with embeddings into Atlas
const result = await collection.insertMany(insertDocuments, options);
console.log("Count of documents inserted: " + result.insertedCount);
} catch (err) {
console.log(err.stack);
}
finally {
await client.close();
}
}
run().catch(console.dir);
Optional function convertEmbeddingsToBSON
import { Binary } from 'mongodb';
// Exported async function to convert provided embeddings to BSON format
export async function convertEmbeddingsToBSON(float32_embeddings) {
try {
// Validate input
if (!Array.isArray(float32_embeddings) || float32_embeddings.length === 0) {
throw new Error("Input must be a non-empty array of embeddings");
}
// Convert float32 embeddings to BSON binary representations
const bsonFloat32Embeddings = float32_embeddings.map(embedding => {
if (!(embedding instanceof Array)) {
throw new Error("Each embedding must be an array of numbers");
}
return Binary.fromFloat32Array(new Float32Array(embedding));
});
// Return the BSON embedding
return bsonFloat32Embeddings[0];
} catch (error) {
console.error('Error during BSON conversion:', error);
throw error; // Re-throw the error for handling by the caller if needed
}
}
The last step to perform a semantic query is to create a vector index, this will allow us to perform vector search queries on our data, and it is really easy to do it with MongoDB, you only need to run the following command in your MongoDB Atlas cluster if you what to see more details about the index definition please see Atlas Vector Search Index.
import { MongoClient } from "mongodb";
// connect to your Atlas deployment
const client = new MongoClient(process.env.ATLAS_CONNECTION_STRING);
async function run() {
try {
const database = client.db("sample_db");
const collection = database.collection("embeddings");
// define your Atlas Vector Search index
const index = {
name: "vector_index",
type: "vectorSearch",
definition: {
fields: [
{
type: "vector",
path: "embedding",
similarity: "dotProduct", // https://www.mongodb.com/docs/atlas/atlas-vector-search/vector-search-type/
numDimensions: 768,
},
],
},
};
// run the helper method
const result = await collection.createSearchIndex(index);
console.log(result);
} finally {
await client.close();
}
}
run().catch(console.dir);
Here we defined a vector index with the name vector_index, and we specified that the field embedding is a vector field with a similarity type of dotProduct and a number of dimensions of 768. This is the same number of dimensions that the embeddings model returns, so it is really important to match this value.
Performing Vector Search Queries
We will create a pipeline to perform a vector search query, this pipeline will use the vectorSearch stage to search for the most relevant documents based on the vector embeddings, and then we will project the results to get only the text and the score of the search.
import { MongoClient } from 'mongodb';
import { getEmbedding } from '../lib/get-embeddings.js';
// MongoDB connection URI and options
const client = new MongoClient(process.env.ATLAS_CONNECTION_STRING);
async function run() {
try {
// Connect to the MongoDB client
await client.connect();
// Specify the database and collection
const database = client.db("sample_db");
const collection = database.collection("embeddings");
// Generate embedding for the search query
const queryEmbedding = await getEmbedding("a sink ship");
// Define the sample vector search pipeline
const pipeline = [
{
$vectorSearch: {
index: "vector_index",
queryVector: queryEmbedding,
path: "embedding",
exact: true,
limit: 10
}
},
{
$project: {
_id: 0,
text: 1,
score: {
$meta: "vectorSearchScore"
}
}
}
];
// run pipeline
const result = collection.aggregate(pipeline);
// print results
for await (const doc of result) {
console.dir(JSON.stringify(doc));
}
} finally {
await client.close();
}
}
run().catch(console.dir);
you will see some output like this where the score is the porcentage of relevance in the multidimentional space of the LLM, other way to see is how close are the outputs from your semantic query input:
{"text":"Titanic: A seventeen-year-old aristocrat falls in love with a kind but poor artist aboard the luxurious, ill-fated R.M.S. Titanic.","score":0.9999999403953552}
{"text":"Avatar: A paraplegic marine dispatched to the moon Pandora on a unique mission becomes torn between following his orders and protecting the world he feels is his home.","score":0.9999999403953552}
{"text":"The Matrix: A computer hacker learns from mysterious rebels about the true nature of his reality and his role in the war against its controllers.","score":0.9999999403953552}
How RAG looks like in code?
We will repet some of the pocess that we already did, with a little difference where we will create a prompt to format our output to our user:
Ingest Data with chunking
Before you run this code, make shure you have enough RAM in your machine, or use a smaller PDF file, or you will stuck here, is optimal that you have a GPU but is not necessay,
Note: If you have a linux machine you can increase your SWAP partition to avoid the RAM issue, but if also take to long so don't worry of your computer get slow.
import { PDFLoader } from "@langchain/community/document_loaders/fs/pdf";
import { RecursiveCharacterTextSplitter } from "langchain/text_splitter";
import { MongoClient } from "mongodb";
import { getEmbedding } from "../lib/get-embeddings.js";
import * as fs from "fs";
async function run() {
const client = new MongoClient(process.env.ATLAS_CONNECTION_STRING);
try {
// Save online PDF as a file
const rawData = await fetch("https://investors.mongodb.com/node/12236/pdf");
const pdfBuffer = await rawData.arrayBuffer();
const pdfData = Buffer.from(pdfBuffer);
fs.writeFileSync("investor-report.pdf", pdfData);
const loader = new PDFLoader(`investor-report.pdf`);
const data = await loader.load();
// Chunk the text from the PDF
const textSplitter = new RecursiveCharacterTextSplitter({
chunkSize: 400,
chunkOverlap: 20,
});
const docs = await textSplitter.splitDocuments(data);
console.log(`Successfully chunked the PDF into ${docs.length} documents.`);
// Connect to your Atlas cluster
await client.connect();
const db = client.db("rag_db");
const collection = db.collection("documents");
console.log("Generating embeddings and inserting documents...");
const insertDocuments = [];
await Promise.all(
docs.map(async (doc) => {
// Generate embeddings using the function that you defined
const embedding = await getEmbedding(doc.pageContent);
// Add the document with the embedding to array of documents for bulk insert
insertDocuments.push({
document: doc,
embedding: embedding,
});
})
);
// Continue processing documents if an error occurs during an operation
const options = { ordered: false };
// Insert documents with embeddings into Atlas
const result = await collection.insertMany(insertDocuments, options);
console.log("Count of documents inserted: " + result.insertedCount);
} catch (err) {
console.log(err.stack);
} finally {
await client.close();
}
}
run().catch(console.dir);
In this code we perform something called overlapping chunking, which allows us to create chunks of text that overlap with each other, this is really important because it allows us to have a better context for the LLM, and also to avoid losing information in the chunks.
Note: Then we have to create our Vector Index, and the code is similar to the one we use before. so you can use the same code and change to match the database and collection names or go to see the code here
Performing a Semantic Search Query
This function only retrieve the most relevant chunks from our database base on our semantic query
import { MongoClient } from 'mongodb';
import { getEmbedding } from '../lib/get-embeddings.js';
// Function to get the results of a vector query
export async function getQueryResults(query) {
// Connect to your Atlas cluster
const client = new MongoClient(process.env.ATLAS_CONNECTION_STRING);
try {
// Get embedding for a query
const queryEmbedding = await getEmbedding(query);
await client.connect();
const db = client.db("rag_db");
const collection = db.collection("documents");
const pipeline = [
{
$vectorSearch: {
index: "vector_index",
queryVector: queryEmbedding,
path: "embedding",
exact: true,
limit: 5
}
},
{
$project: {
_id: 0,
document: 1,
}
}
];
// Retrieve documents from Atlas using this Vector Search query
const result = collection.aggregate(pipeline);
const arrayOfQueryDocs = [];
for await (const doc of result) {
arrayOfQueryDocs.push(doc);
}
return arrayOfQueryDocs;
} catch (err) {
console.log(err.stack);
}
finally {
await client.close();
}
}
After that the only missing step is to create a prompt to pass the results to the LLM.
Creating a Prompt for the LLM
This function will create a prompt for the LLM using the results from the semantic search query, and then we will pass the prompt to the LLM to get the answer.
import { getQueryResults } from "./retrieve-documents.js";
import { HfInference } from "@huggingface/inference";
async function run() {
try {
// Specify search query and retrieve relevant documents
const query = "fastest animal";
const documents = await getQueryResults(query);
// Build a string representation of the retrieved documents to use in the prompt
let textDocuments = "";
documents.forEach((doc) => {
textDocuments += doc.document.pageContent;
});
const question = "What ais the top 3 fastes animal in earth?";
// Create a prompt consisting of the question and context to pass to the LLM
const prompt = `Answer the following question based on the given context. if the given context can't asnware the question please response only with "I don't know"
Question: {${question}}
Context: {${textDocuments}}
`;
// Connect to Hugging Face, using the access token from the environment file
const hf = new HfInference(process.env.HUGGING_FACE_ACCESS_TOKEN);
const llm = hf.endpoint(
"https://api-inference.huggingface.co/models/mistralai/Mistral-7B-Instruct-v0.3"
);
// Prompt the LLM to answer the question using the
// retrieved documents as the context
const output = await llm.chatCompletion({
model: "mistralai/Mistral-7B-Instruct-v0.2",
messages: [{ role: "user", content: prompt }],
max_tokens: 150,
});
// Output the LLM's response as text.
console.log(output.choices[0].message.content);
} catch (err) {
console.log(err.stack);
}
}
run().catch(console.dir);
The magic here happend on the instruction that you pass to the model in the prompt, to perform the best and more relevant output for your porpuse.
Conclusion
If you are here and you understand all the process, congratulations! you have learned the fundamentals of building applications with LLMs powered by MongoDB.
You have learned about vector embeddings, vector search, semantic search, and vector databases. And basically you have learned the necessary to create your own arquitecture and also create an Agent, How? well if you can add a MCP in the middle of the process there you have an Agent, you can use the MCP to perform actions based on the LLM's response, or to perform more complex queries, or to perform more complex actions.
The limit here is your imagination, you see that you don't need to spend a single cent to create your own applications with LLMs powered by MongoDB, you can use the free tier of MongoDB Atlas and the free models from Hugging Face.